Database Connection Limits And Scaling
29 Jan 2023
Introduction
This post is a quick analysis on scaling your databases in regards to connection limits.
Current Work Background at Time of Writing
At my current job, we use AWS RDS for our MySQL database and “bare metal” EC2 instances for our Elasticsearch.
Before my time, the product I was working on was using solely MySQL for their database needs. However they ran into scaling issues, specifically connection limits issues.
Let’s do some math
Our backend app servers have a max auto scaling policy of 80 instances. Each EC2 instance runs a Puma server that boots up 4 Rails Workers. Each Rails worker will open up 32 MySQL database connections.
At max load, the equation to determine the most active MySQL connections would like this:
80 instances * 4 Puma Workers * 32 Connections = 10,240 connections
However that isn’t all. We also have a sidekiq worker instance running 12 threads. Each thread runs a rails worker instance with 55 database connections.
The worker math will be as follows:
1 instance * 12 sidekiq threads * 55 connections = 660 connections
Total connections and scaling
10,240 app server connections + 660 worker server connections = 10,900 connections
10,900 connections is right below the cutoff for the max connections of our RDS instance type(db.r5.4xlarge), which is 10,922 connections.
(Note: A good reference for connection limits and RDS instance types: https://sysadminxpert.com/aws-rds-max-connections-limit/
This razor thin margin of error was not enough to avoid database connection errors. A good explanation of this is because database connections are NOT a “primitive” unit of measurement. It is in abstraction and estimation of how much memory is available to maintain connections. Once we realize that connections are just computer memory, it makes sense that these max connection numbers are not absolutes. Of course, there are other factors at play, notably bad logic in your application layer that might cause hanging connections, long running request logic, and plethora of other edge cases.
Possible solutions
- Upgrading instance types
- Switching to a new database solution
- Refactoring our application layer to require less database connections
The solution we DID NOT go with
1. Upgrading instance types
AWS RDS connections are based on memory (RAM). RDS RAM is based on the underlying instance type fueling the database servers. The easiest solution and the most expensive solution is to upgrade the underlying instance type of our AWS RDS service.
We used memory optimized db.r* series instances in a multi AZ environment. Our specific size is a 4xlarge and the next biggest size to fulfill our needs would be a db.r* series 8xlarge size. Look at the price differential below from the AWS RDS pricing chart:
https://aws.amazon.com/rds/mysql/pricing/?pg=pr&loc=2
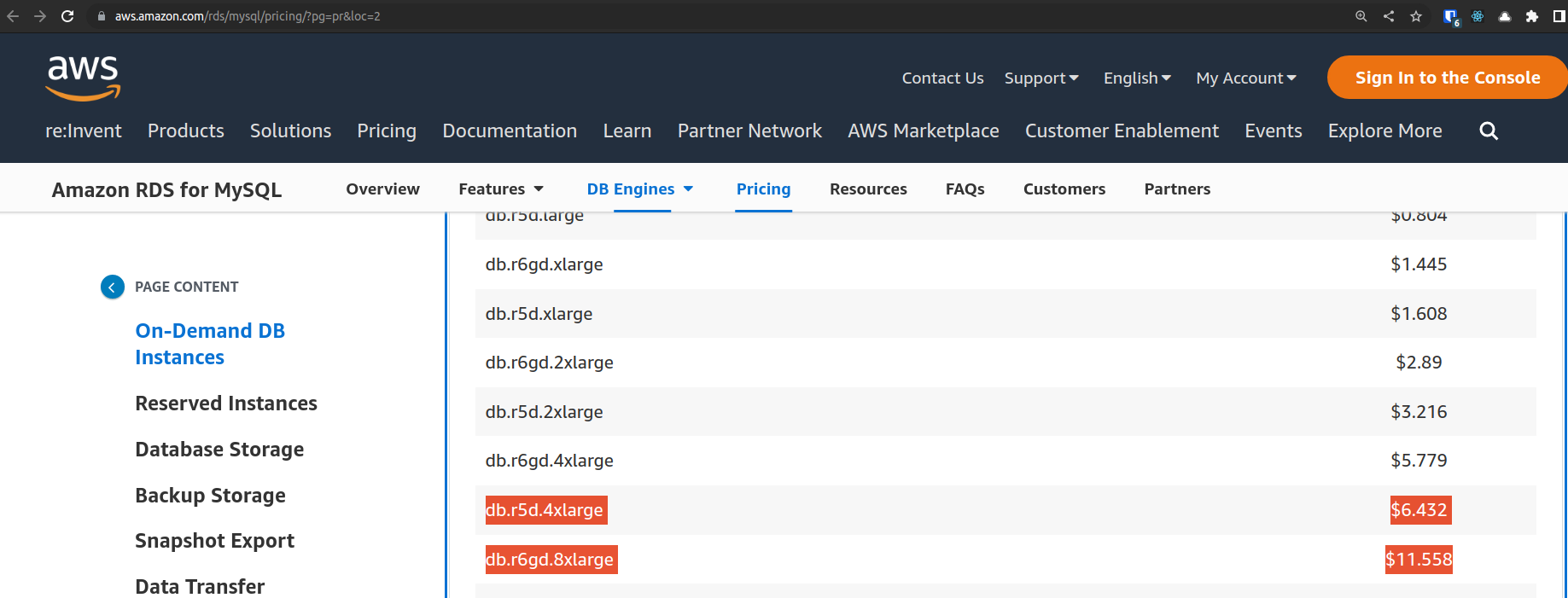
Our current pricing is $6.432 per hour, the upgrade would cost $11.558. That’s almost an 80% increase in database costs.
Pros of this solution:
- Easy
- No changes needed to application logic
Cons of this solution:
- Expensive
- Won’t solve other issues if you have them, ie. Long Locking Periods, Limited write throughput due to atomicity
The solution we did go with
We went with 2 solutions:
- Switching to a new database solution, specifically Elasticsearch
- Refactoring our application layer to require less database connections through caching and moving read heavy data to elasticsearch
Reasons to switch to Elasticsearch
- Faster read times for large datasets.
- Writes are NOT transactional allowing for faster (but less secure) writes.
- More fine tuned search functionality.
- Easier horizontal scaling compared to AWS RDS.
- Do not have to worry about database connection limits.
The product my team was working on was read heavy with varying traffic load throughout the day and had millions of records to search from at all times. We believed that if we converted all lot of the ready heavy endpoints to use exclusively or mostly Elasticsearch, we could alleviate our database connection issues, which it did.
Switching to Elasticsearch Cons
Switching some of our domain logic to Elasticsearch was not easy. We had to do a mental reframing in our application.
It added a lot more complexity to our application. Converting our active model records to elastic search wasn’t a 1 to 1 conversion. We actually had to create new models to better encapsulate our application logic and Elasticsearch quirks. Specifically we had to switch from the Active Record Design pattern into a more Query Object design pattern.
Our ingestion from upstream data sources also became complex and messy. This blog from ClearScale does a great job explaning their process to switching to ElasticSearch and it represents our flow very similarly Essentially we had to add on an Elasticsearch ingestion layer that read from a completed MySQL upstream ingestion.
Caching Benefits
Caching is the act of storing data, most of the time in memory, to generate faster read times. The caching solution we used was Memcache and Redis through AWS Elasticache. We already had these caching solutions implemented but we heavily refactored our endpoints to use caching more aggressively.
Our strategy to cache data was to create key value pairs unique to the user that was read multiple times during a session. The data we render is heavily customized to the logged in user so we implemented the user_id as part of our key for each entry of cache data. For example if we had recommendations stored specificly for a user, we would cache those recommendations with a key like this "#{user_id}_reccomendations"
The benefit of this approach is that we can offset sql reads by last read time specific for the user and decrease SQL reads altogether.
Caching Implementation Nuance
We used memcache on data that could be destroyed. We used Redis on data that was vital to our application and would have to be persisted for the lifetime of the application.
Caching Cons
We realized that AWS EC2 instances also have bandwidth limitations that scales to the instance size. Heavily caching our data caused Network Bandwidth issues, but that is a discussion for another time.
Also a lot of our data cached was schemaless. Of course we could have created our own schema objects that would be used to serialize and deserialize data, but nothing actually stops the application layer for storing schema breaking data.
Final Learnings
Elasticsearch is a great database, it is highly performant and scaling horizontally is for the most part an easy process. It doesn’t have to transactional guarantees as MySQL but we found that for our read heavy application we did not need the same safety guarantees.
Caching is an awesome and easy technique to alleviate database loads and decrease response times but beware of network bandwidth issues especially during peak load if your have a highly loaded cache.